- Docs Home
- About TiDB Cloud
- Get Started
- Develop Applications
- Overview
- Quick Start
- Build a TiDB Developer Cluster
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Manage Cluster
- Plan Your Cluster
- Create a TiDB Cluster
- Connect to Your TiDB Cluster
- Set Up VPC Peering Connections
- Use an HTAP Cluster with TiFlash
- Scale a TiDB Cluster
- Upgrade a TiDB Cluster
- Delete a TiDB Cluster
- Use TiDB Cloud API (Beta)
- Migrate Data
- Import Sample Data
- Migrate Data into TiDB
- Configure Amazon S3 Access and GCS Access
- Migrate from MySQL-Compatible Databases
- Migrate Incremental Data from MySQL-Compatible Databases
- Migrate from Amazon Aurora MySQL in Bulk
- Import or Migrate from Amazon S3 or GCS to TiDB Cloud
- Import CSV Files from Amazon S3 or GCS into TiDB Cloud
- Import Apache Parquet Files from Amazon S3 or GCS into TiDB Cloud
- Troubleshoot Access Denied Errors during Data Import from Amazon S3
- Export Data from TiDB
- Back Up and Restore
- Monitor and Alert
- Overview
- Built-in Monitoring
- Built-in Alerting
- Third-Party Monitoring Integrations
- Tune Performance
- Overview
- Analyze Performance
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- TiKV Follower Read
- Coprocessor Cache
- Garbage Collection (GC)
- Tune TiFlash performance
- Manage User Access
- Billing
- Reference
- TiDB Cluster Architecture
- TiDB Cloud Cluster Limits and Quotas
- TiDB Limitations
- SQL
- Explore SQL with TiDB
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ALTER DATABASEALTER INDEXALTER TABLEALTER TABLE COMPACTALTER USERANALYZE TABLEBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]MODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACEREVOKE <privileges>REVOKE <role>ROLLBACKSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Read Historical Data
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_INFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESKEY_COLUMN_USAGEPARTITIONSPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVIEWS
- System Variables
- API Reference
- Storage Engines
- Dumpling
- Table Filter
- Troubleshoot Inconsistency Between Data and Indexes
- FAQs
- Release Notes
- Support
- Glossary
TiKV Overview
TiKV is a distributed and transactional key-value database, which provides transactional APIs with ACID compliance. With the implementation of the Raft consensus algorithm and consensus state stored in RocksDB, TiKV guarantees data consistency between multiple replicas and high availability. As the storage layer of the TiDB distributed database, TiKV provides the read and write service, and persist the written data from applications. It also stores the statistics data of the TiDB cluster.
Architecture Overview
TiKV implements the multi-raft-group replica mechanism based on the design of Google Spanner. A Region is a basic unit of the key-value data movement and refers to a data range in a Store. Each Region is replicated to multiple nodes. These multiple replicas form a Raft group. A replica of a Region is called a Peer. Typically there are 3 peers in a Region. One of them is the leader, which provides the read and write services. The PD component balances all the Regions automatically to guarantee that the read and write throughput is balanced among all the nodes in the TiKV cluster. With PD and carefully designed Raft groups, TiKV excels in horizontal scalability and can easily scale to store more than 100 TBs of data.
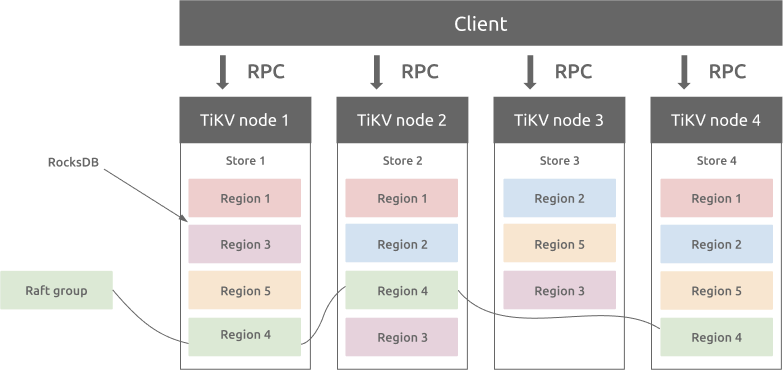
Region and RocksDB
There is a RocksDB database within each Store and it stores data into the local disk. All the Region data are stored in the same RocksDB instance in each Store. All the logs used for the Raft consensus algorithm is stored in another RocksDB instance in each Store. This is because the performance of sequential I/O is better than random I/O. With different RocksDB instances storing raft logs and Region data, TiKV combines all the data write operations of raft logs and TiKV Regions into one I/O operation to improve the performance.
Region and Raft Consensus Algorithm
Data consistency between replicas of a Region is guaranteed by the Raft Consensus Algorithm. Only the leader of the Region can provide the writing service, and only when the data is written to the majority of replicas of a Region, the write operation succeeds.
When the size of a Region exceeds a threshold, which is 144 MB by default, TiKV splits it to two or more Regions. This operation guarantees the size of all the Regions in the cluster is nearly the same, which helps the PD component to balance Regions among nodes in a TiKV cluster. When the size of a Region is smaller than the threshold, TiKV merges the two smaller adjacent Regions into one Region.
When PD moves a replica from one TiKV node to another, it firstly adds a Learner replica on the target node, after the data in the Learner replica is nearly the same as that in the Leader replica, PD changes it to a Follower replica and removes the Follower replica on the source node.
Moving Leader replica from one node to another has a similar mechanism. The difference is that after the Learner replica becomes the Follower replica, there is a "Leader Transfer" operation in which the Follower replica actively proposes an election to elect itself as the Leader. Finally, the new Leader removes the old Leader replica in the source node.
Distributed Transaction
TiKV supports distributed transactions. Users (or TiDB) can write multiple key-value pairs without worrying about whether they belong to the same Region. TiKV uses two-phase commit to achieve ACID constraints. See TiDB Optimistic Transaction Model for details.
TiKV Coprocessor
TiDB pushes some data computation logic to TiKV Coprocessor. TiKV Coprocessor processes the computation for each Region. Each request sent to TiKV Coprocessor only involves the data of one Region.