- Docs Home
- About TiDB
- Quick Start
- Develop
- Overview
- Quick Start
- Build a TiDB Cluster in TiDB Cloud (Developer Tier)
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Third-party Support
- Deploy
- Software and Hardware Requirements
- Environment Configuration Checklist
- Plan Cluster Topology
- Install and Start
- Verify Cluster Status
- Test Cluster Performance
- Migrate
- Overview
- Migration Tools
- Migration Scenarios
- Migrate from Aurora
- Migrate MySQL of Small Datasets
- Migrate MySQL of Large Datasets
- Migrate and Merge MySQL Shards of Small Datasets
- Migrate and Merge MySQL Shards of Large Datasets
- Migrate from CSV Files
- Migrate from SQL Files
- Migrate from One TiDB Cluster to Another TiDB Cluster
- Migrate from TiDB to MySQL-compatible Databases
- Advanced Migration
- Integrate
- Overview
- Integration Scenarios
- Maintain
- Monitor and Alert
- Troubleshoot
- TiDB Troubleshooting Map
- Identify Slow Queries
- Analyze Slow Queries
- SQL Diagnostics
- Identify Expensive Queries Using Top SQL
- Identify Expensive Queries Using Logs
- Statement Summary Tables
- Troubleshoot Hotspot Issues
- Troubleshoot Increased Read and Write Latency
- Save and Restore the On-Site Information of a Cluster
- Troubleshoot Cluster Setup
- Troubleshoot High Disk I/O Usage
- Troubleshoot Lock Conflicts
- Troubleshoot TiFlash
- Troubleshoot Write Conflicts in Optimistic Transactions
- Troubleshoot Inconsistency Between Data and Indexes
- Performance Tuning
- Tuning Guide
- Configuration Tuning
- System Tuning
- Software Tuning
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- Tutorials
- TiDB Tools
- Overview
- Use Cases
- Download
- TiUP
- Documentation Map
- Overview
- Terminology and Concepts
- Manage TiUP Components
- FAQ
- Troubleshooting Guide
- Command Reference
- Overview
- TiUP Commands
- TiUP Cluster Commands
- Overview
- tiup cluster audit
- tiup cluster check
- tiup cluster clean
- tiup cluster deploy
- tiup cluster destroy
- tiup cluster disable
- tiup cluster display
- tiup cluster edit-config
- tiup cluster enable
- tiup cluster help
- tiup cluster import
- tiup cluster list
- tiup cluster patch
- tiup cluster prune
- tiup cluster reload
- tiup cluster rename
- tiup cluster replay
- tiup cluster restart
- tiup cluster scale-in
- tiup cluster scale-out
- tiup cluster start
- tiup cluster stop
- tiup cluster template
- tiup cluster upgrade
- TiUP DM Commands
- Overview
- tiup dm audit
- tiup dm deploy
- tiup dm destroy
- tiup dm disable
- tiup dm display
- tiup dm edit-config
- tiup dm enable
- tiup dm help
- tiup dm import
- tiup dm list
- tiup dm patch
- tiup dm prune
- tiup dm reload
- tiup dm replay
- tiup dm restart
- tiup dm scale-in
- tiup dm scale-out
- tiup dm start
- tiup dm stop
- tiup dm template
- tiup dm upgrade
- TiDB Cluster Topology Reference
- DM Cluster Topology Reference
- Mirror Reference Guide
- TiUP Components
- PingCAP Clinic Diagnostic Service
- TiDB Operator
- Dumpling
- TiDB Lightning
- TiDB Data Migration
- About TiDB Data Migration
- Architecture
- Quick Start
- Deploy a DM cluster
- Tutorials
- Advanced Tutorials
- Maintain
- Cluster Upgrade
- Tools
- Performance Tuning
- Manage Data Sources
- Manage Tasks
- Export and Import Data Sources and Task Configurations of Clusters
- Handle Alerts
- Daily Check
- Reference
- Architecture
- Command Line
- Configuration Files
- OpenAPI
- Compatibility Catalog
- Secure
- Monitoring and Alerts
- Error Codes
- Glossary
- Example
- Troubleshoot
- Release Notes
- Backup & Restore (BR)
- Point-in-Time Recovery
- TiDB Binlog
- TiCDC
- Dumpling
- sync-diff-inspector
- TiSpark
- Reference
- Cluster Architecture
- Key Monitoring Metrics
- Secure
- Privileges
- SQL
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ADMIN SHOW TELEMETRYALTER DATABASEALTER INDEXALTER INSTANCEALTER PLACEMENT POLICYALTER TABLEALTER TABLE COMPACTALTER TABLE SET TIFLASH MODEALTER USERANALYZE TABLEBACKUPBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE PLACEMENT POLICYCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP PLACEMENT POLICYDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]LOAD DATALOAD STATSMODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACERESTOREREVOKE <privileges>REVOKE <role>ROLLBACKSAVEPOINTSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [BACKUPS|RESTORES]SHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CONFIGSHOW CREATE PLACEMENT POLICYSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLACEMENTSHOW PLACEMENT FORSHOW PLACEMENT LABELSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Garbage Collection (GC)
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Placement Rules in SQL
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_CONFIGCLUSTER_HARDWARECLUSTER_INFOCLUSTER_LOADCLUSTER_LOGCLUSTER_SYSTEMINFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESINSPECTION_RESULTINSPECTION_RULESINSPECTION_SUMMARYKEY_COLUMN_USAGEMETRICS_SUMMARYMETRICS_TABLESPARTITIONSPLACEMENT_POLICIESPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVARIABLES_INFOVIEWS
METRICS_SCHEMA
- UI
- TiDB Dashboard
- Overview
- Maintain
- Access
- Overview Page
- Cluster Info Page
- Top SQL Page
- Key Visualizer Page
- Metrics Relation Graph
- SQL Statements Analysis
- Slow Queries Page
- Cluster Diagnostics
- Monitoring Page
- Search Logs Page
- Instance Profiling
- Session Management and Configuration
- FAQ
- CLI
- Command Line Flags
- Configuration File Parameters
- System Variables
- Storage Engines
- Telemetry
- Errors Codes
- Table Filter
- Schedule Replicas by Topology Labels
- FAQs
- Release Notes
- All Releases
- Release Timeline
- TiDB Versioning
- TiDB Installation Packages
- v6.2
- v6.1
- v6.0
- v5.4
- v5.3
- v5.2
- v5.1
- v5.0
- v4.0
- v3.1
- v3.0
- v2.1
- v2.0
- v1.0
- Glossary
TiDB Pessimistic Transaction Mode
To make the usage of TiDB closer to traditional databases and reduce the cost of migration, starting from v3.0, TiDB supports the pessimistic transaction mode on top of the optimistic transaction model. This document describes the features of the TiDB pessimistic transaction mode.
Starting from v3.0.8, newly created TiDB clusters use the pessimistic transaction mode by default. However, this does not affect your existing cluster if you upgrade it from v3.0.7 or earlier to v3.0.8 or later. In other words, only newly created clusters default to using the pessimistic transaction mode.
Switch transaction mode
You can set the transaction mode by configuring the tidb_txn_mode system variable. The following command sets all explicit transactions (that is, non-autocommit transactions) executed by newly created sessions in the cluster to the pessimistic transaction mode:
SET GLOBAL tidb_txn_mode = 'pessimistic';
You can also explicitly enable the pessimistic transaction mode by executing the following SQL statements:
BEGIN PESSIMISTIC;
BEGIN /*T! PESSIMISTIC */;
The BEGIN PESSIMISTIC; and BEGIN OPTIMISTIC; statements take precedence over the tidb_txn_mode system variable. Transactions started with these two statements ignore the system variable and support using both the pessimistic and optimistic transaction modes.
Behaviors
Pessimistic transactions in TiDB behave similarly to those in MySQL. See the minor differences in Difference with MySQL InnoDB.
For pessimistic transactions, TiDB introduces snapshot read and current read.
Snapshot read: it is an unlocked read that reads a version committed before the transaction starts. The read in the
SELECTstatement is a snapshot read.Current read: it is a locked read that reads the latest committed version. The read in the
UPDATE,DELETE,INSERT, orSELECT FOR UPDATEstatement is a current read.The following examples provide a detailed description of snapshot read and current read.
Session 1 Session 2 Session 3 CREATE TABLE t (a INT); INSERT INTO T VALUES(1); BEGIN PESSIMISTIC; UPDATE t SET a = a + 1; BEGIN PESSIMISTIC; SELECT * FROM t; -- Use the snapshot read to read the version committed before the current transaction starts. The result returns a=1. BEGIN PESSIMISTIC; SELECT * FROM t FOR UPDATE; -- Use the current read. Wait for the lock. COMMIT; -- Release the lock. The SELECT FOR UPDATE operation of session 3 obtains the lock and TiDB uses the current read to read the latest committed version. The result returns a=2. SELECT * FROM t; -- Use the snapshot read to read the version committed before the current transaction starts. The result returns a=1.
When you execute
UPDATE,DELETEorINSERTstatements, the latest committed data is read, data is modified, and a pessimistic lock is applied on the modified rows.For
SELECT FOR UPDATEstatements, a pessimistic lock is applied on the latest version of the committed data, instead of on the modified rows.Locks will be released when the transaction is committed or rolled back. Other transactions attempting to modify the data are blocked and have to wait for the lock to be released. Transactions attempting to read the data are not blocked, because TiDB uses multi-version concurrency control (MVCC).
If several transactions are trying to acquire each other's respective locks, a deadlock will occur. This is automatically detected, and one of the transactions will randomly be terminated with a MySQL-compatible error code
1213returned.Transactions will wait up to
innodb_lock_wait_timeoutseconds (default: 50) to acquire new locks. When this timeout is reached, a MySQL-compatible error code1205is returned. If multiple transactions are waiting for the same lock, the order of priority is approximately based on thestart tsof the transaction.TiDB supports both the optimistic transaction mode and pessimistic transaction mode in the same cluster. You can specify either mode for transaction execution.
TiDB supports the
FOR UPDATE NOWAITsyntax and does not block and wait for locks to be released. Instead, a MySQL-compatible error code3572is returned.If the
Point GetandBatch Point Getoperators do not read data, they still lock the given primary key or unique key, which blocks other transactions from locking or writing data to the same primary key or unique key.TiDB supports the
FOR UPDATE OF TABLESsyntax. For a statement that joins multiple tables, TiDB only applies pessimistic locks on the rows that are associated with the tables inOF TABLES.
Difference with MySQL InnoDB
When TiDB executes DML or
SELECT FOR UPDATEstatements that use range in the WHERE clause, concurrent DML statements within the range are not blocked.For example:
CREATE TABLE t1 ( id INT NOT NULL PRIMARY KEY, pad1 VARCHAR(100) ); INSERT INTO t1 (id) VALUES (1),(5),(10);BEGIN /*T! PESSIMISTIC */; SELECT * FROM t1 WHERE id BETWEEN 1 AND 10 FOR UPDATE;BEGIN /*T! PESSIMISTIC */; INSERT INTO t1 (id) VALUES (6); -- blocks only in MySQL UPDATE t1 SET pad1='new value' WHERE id = 5; -- blocks waiting in both MySQL and TiDBThis behavior is because TiDB does not currently support gap locking.
TiDB does not support
SELECT LOCK IN SHARE MODE.When
SELECT LOCK IN SHARE MODEis executed, it has the same effect as that without the lock, so the read or write operation of other transactions is not blocked.DDL may result in failure of the pessimistic transaction commit.
When DDL is executed in MySQL, it might be blocked by the transaction that is being executed. However, in this scenario, the DDL operation is not blocked in TiDB, which leads to failure of the pessimistic transaction commit:
ERROR 1105 (HY000): Information schema is changed. [try again later]. TiDB executes theTRUNCATE TABLEstatement during the transaction execution, which might result in thetable doesn't existerror.After executing
START TRANSACTION WITH CONSISTENT SNAPSHOT, MySQL can still read the tables that are created later in other transactions, while TiDB cannot.The autocommit transactions prefer the optimistic locking.
When using the pessimistic model, the autocommit transactions first try to commit the statement using the optimistic model that has less overhead. If a write conflict occurs, the pessimistic model is used for transaction retry. Therefore, if
tidb_retry_limitis set to0, the autocommit transaction still reports theWrite Conflicterror when a write conflict occurs.The autocommit
SELECT FOR UPDATEstatement does not wait for lock.The data read by
EMBEDDED SELECTin the statement is not locked.Open transactions in TiDB do not block garbage collection (GC). By default, this limits the maximum execution time of pessimistic transactions to 1 hour. You can modify this limit by editing
max-txn-ttlunder[performance]in the TiDB configuration file.
Isolation level
TiDB supports the following two isolation levels in the pessimistic transaction mode:
Repeatable Read by default, which is the same as MySQL.
NoteIn this isolation level, DML operations are performed based on the latest committed data. The behavior is the same as MySQL, but differs from the optimistic transaction mode in TiDB. See Difference between TiDB and MySQL Repeatable Read.
Read Committed. You can set this isolation level using the
SET TRANSACTIONstatement.
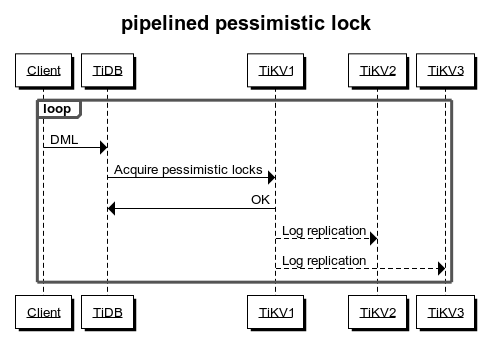
Pipelined locking process
Adding a pessimistic lock requires writing data into TiKV. The response of successfully adding a lock can only be returned to TiDB after commit and apply through Raft. Therefore, compared with optimistic transactions, the pessimistic transaction mode inevitably has higher latency.
To reduce the overhead of locking, TiKV implements the pipelined locking process: when the data meets the requirements for locking, TiKV immediately notifies TiDB to execute subsequent requests and writes into the pessimistic lock asynchronously. This process reduces most latency and significantly improves the performance of pessimistic transactions. However, when network partition occurs in TiKV or a TiKV node is down, the asynchronous write into the pessimistic lock might fail and affect the following aspects:
Other transactions that modify the same data cannot be blocked. If the application logic relies on locking or lock waiting mechanisms, the correctness of the application logic is affected.
There is a low probability that the transaction commit fails, but it does not affect the correctness of the transactions.
If the application logic relies on the locking or lock waiting mechanisms, or if you want to guarantee as much as possible the success rate of transaction commits even in the case of TiKV cluster anomalies, you should disable the pipelined locking feature.
This feature is enabled by default. To disable it, modify the TiKV configuration:
[pessimistic-txn]
pipelined = false
If the TiKV cluster is v4.0.9 or later, you can also dynamically disable this feature by modifying TiKV configuration online:
set config tikv pessimistic-txn.pipelined='false';
If the application logic relies on the locking or lock waiting mechanisms, or if you want to guarantee as much as possible the success rate of transaction commits even in the case of TiKV cluster anomalies, you can contact PingCAP Support to disable the pipelined locking feature.
In-memory pessimistic lock
In v6.0.0, TiKV introduces the feature of in-memory pessimistic lock. When this feature is enabled, pessimistic locks are usually stored in the memory of the Region leader only, and are not persisted to disk or replicated through Raft to other replicas. This feature can greatly reduce the overhead of acquiring pessimistic locks and improve the throughput of pessimistic transactions.
When the memory usage of in-memory pessimistic locks exceeds the memory threshold of the Region or the TiKV node, the acquisition of pessimistic locks turns to the pipelined locking process. When the Region is merged or the leader is transferred, to avoid the loss of the pessimistic lock, TiKV writes the in-memory pessimistic lock to disk and replicates it to other replicas.
The in-memory pessimistic lock performs similarly to the pipelined locking process, which does not affect the lock acquisition when the cluster is healthy. However, when network isolation occurs in TiKV or a TiKV node is down, the acquired pessimistic lock might be lost.
If the application logic relies on the lock acquiring or lock waiting mechanism, or if you want to guarantee as much as possible the success rate of transaction commits even when the cluster is in an abnormal state, you need to disable the in-memory pessimistic lock feature.
This feature is enabled by default. To disable it, modify the TiKV configuration:
[pessimistic-txn]
in-memory = false
To dynamically disable this feature, modify the TiKV configuration online:
set config tikv pessimistic-txn.in-memory='false';