- Docs Home
- About TiDB
- Quick Start
- Develop
- Overview
- Quick Start
- Build a TiDB Cluster in TiDB Cloud (Developer Tier)
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Third-party Support
- Deploy
- Software and Hardware Requirements
- Environment Configuration Checklist
- Plan Cluster Topology
- Install and Start
- Verify Cluster Status
- Test Cluster Performance
- Migrate
- Overview
- Migration Tools
- Migration Scenarios
- Migrate from Aurora
- Migrate MySQL of Small Datasets
- Migrate MySQL of Large Datasets
- Migrate and Merge MySQL Shards of Small Datasets
- Migrate and Merge MySQL Shards of Large Datasets
- Migrate from CSV Files
- Migrate from SQL Files
- Migrate from One TiDB Cluster to Another TiDB Cluster
- Migrate from TiDB to MySQL-compatible Databases
- Advanced Migration
- Integrate
- Maintain
- Monitor and Alert
- Troubleshoot
- TiDB Troubleshooting Map
- Identify Slow Queries
- Analyze Slow Queries
- SQL Diagnostics
- Identify Expensive Queries Using Top SQL
- Identify Expensive Queries Using Logs
- Statement Summary Tables
- Troubleshoot Hotspot Issues
- Troubleshoot Increased Read and Write Latency
- Save and Restore the On-Site Information of a Cluster
- Troubleshoot Cluster Setup
- Troubleshoot High Disk I/O Usage
- Troubleshoot Lock Conflicts
- Troubleshoot TiFlash
- Troubleshoot Write Conflicts in Optimistic Transactions
- Troubleshoot Inconsistency Between Data and Indexes
- Performance Tuning
- Tuning Guide
- Configuration Tuning
- System Tuning
- Software Tuning
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- Tutorials
- TiDB Tools
- Overview
- Use Cases
- Download
- TiUP
- Documentation Map
- Overview
- Terminology and Concepts
- Manage TiUP Components
- FAQ
- Troubleshooting Guide
- Command Reference
- Overview
- TiUP Commands
- TiUP Cluster Commands
- Overview
- tiup cluster audit
- tiup cluster check
- tiup cluster clean
- tiup cluster deploy
- tiup cluster destroy
- tiup cluster disable
- tiup cluster display
- tiup cluster edit-config
- tiup cluster enable
- tiup cluster help
- tiup cluster import
- tiup cluster list
- tiup cluster patch
- tiup cluster prune
- tiup cluster reload
- tiup cluster rename
- tiup cluster replay
- tiup cluster restart
- tiup cluster scale-in
- tiup cluster scale-out
- tiup cluster start
- tiup cluster stop
- tiup cluster template
- tiup cluster upgrade
- TiUP DM Commands
- Overview
- tiup dm audit
- tiup dm deploy
- tiup dm destroy
- tiup dm disable
- tiup dm display
- tiup dm edit-config
- tiup dm enable
- tiup dm help
- tiup dm import
- tiup dm list
- tiup dm patch
- tiup dm prune
- tiup dm reload
- tiup dm replay
- tiup dm restart
- tiup dm scale-in
- tiup dm scale-out
- tiup dm start
- tiup dm stop
- tiup dm template
- tiup dm upgrade
- TiDB Cluster Topology Reference
- DM Cluster Topology Reference
- Mirror Reference Guide
- TiUP Components
- PingCAP Clinic Diagnostic Service
- TiDB Operator
- Dumpling
- TiDB Lightning
- TiDB Data Migration
- About TiDB Data Migration
- Architecture
- Quick Start
- Deploy a DM cluster
- Tutorials
- Advanced Tutorials
- Maintain
- Cluster Upgrade
- Tools
- Performance Tuning
- Manage Data Sources
- Manage Tasks
- Export and Import Data Sources and Task Configurations of Clusters
- Handle Alerts
- Daily Check
- Reference
- Architecture
- Command Line
- Configuration Files
- OpenAPI
- Compatibility Catalog
- Secure
- Monitoring and Alerts
- Error Codes
- Glossary
- Example
- Troubleshoot
- Release Notes
- Backup & Restore (BR)
- TiDB Binlog
- TiCDC
- Dumpling
- sync-diff-inspector
- TiSpark
- Reference
- Cluster Architecture
- Key Monitoring Metrics
- Secure
- Privileges
- SQL
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ADMIN SHOW TELEMETRYALTER DATABASEALTER INDEXALTER INSTANCEALTER PLACEMENT POLICYALTER TABLEALTER TABLE COMPACTALTER USERANALYZE TABLEBACKUPBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE PLACEMENT POLICYCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP PLACEMENT POLICYDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]LOAD DATALOAD STATSMODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACERESTOREREVOKE <privileges>REVOKE <role>ROLLBACKSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [BACKUPS|RESTORES]SHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CONFIGSHOW CREATE PLACEMENT POLICYSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLACEMENTSHOW PLACEMENT FORSHOW PLACEMENT LABELSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Garbage Collection (GC)
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Placement Rules in SQL
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_CONFIGCLUSTER_HARDWARECLUSTER_INFOCLUSTER_LOADCLUSTER_LOGCLUSTER_SYSTEMINFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESINSPECTION_RESULTINSPECTION_RULESINSPECTION_SUMMARYKEY_COLUMN_USAGEMETRICS_SUMMARYMETRICS_TABLESPARTITIONSPLACEMENT_POLICIESPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVIEWS
METRICS_SCHEMA
- UI
- TiDB Dashboard
- Overview
- Maintain
- Access
- Overview Page
- Cluster Info Page
- Top SQL Page
- Key Visualizer Page
- Metrics Relation Graph
- SQL Statements Analysis
- Slow Queries Page
- Cluster Diagnostics
- Search Logs Page
- Instance Profiling
- Session Management and Configuration
- FAQ
- CLI
- Command Line Flags
- Configuration File Parameters
- System Variables
- Storage Engines
- Telemetry
- Errors Codes
- Table Filter
- Schedule Replicas by Topology Labels
- FAQs
- Release Notes
- All Releases
- Release Timeline
- TiDB Versioning
- v6.1
- v6.0
- v5.4
- v5.3
- v5.2
- v5.1
- v5.0
- v4.0
- v3.1
- v3.0
- v2.1
- v2.0
- v1.0
- Glossary
Merge and Migrate Data from Sharded Tables in Optimistic Mode
This document introduces the sharding support feature provided by Data Migration (DM) in the optimistic mode. This feature allows you to merge and migrate the data of tables with the same or different table schema(s) in the upstream MySQL or MariaDB instances into one same table in the downstream TiDB.
If you do not have an in-depth understanding of the optimistic mode and its restrictions, it is NOT recommended to use this mode. Otherwise, migration interruption or even data inconsistency might occur.
Background
DM supports executing DDL statements on sharded tables online, which is called sharding DDL, and uses the "pessimistic mode" by default. In this mode, when a DDL statement is executed in an upstream sharded table, data migration of this table is paused until the same DDL statement is executed in all other sharded tables. Only by then this DDL statement is executed in the downstream and data migration resumes.
The pessimistic mode guarantees that the data migrated to the downstream is always correct, but it pauses the data migration, which is bad for making A/B changes in the upstream. In some cases, users might spend a long time executing DDL statements in a single sharded table and change the schemas of other sharded tables only after a period of validation. In the pessimistic mode, these DDL statements block data migration and cause many binlog events to pile up.
Therefore, an "optimistic mode" is needed. In this mode, a DDL statement executed on a sharded table is automatically converted to a statement that is compatible with other sharded tables, and then immediately migrated to the downstream. In this way, the DDL statement does not block any sharded table from executing DML migration.
Configuration of the optimistic mode
To use the optimistic mode, specify the shard-mode item in the task configuration file as optimistic. For the detailed sample configuration file, see DM Advanced Task Configuration File.
Restrictions
It takes some risks to use the optimistic mode. Follow these rules when you use it:
Ensure that the schema of every sharded table is consistent with each other before and after you execute a batch of DDL statements.
If you perform an A/B test, perform the test ONLY on one sharded table.
After the A/B test is finished, migrate only the most direct DDL statement(s) to the final schema. Do not re-execute every right or wrong step of the test.
For example, if you have executed
ADD COLUMN A INT; DROP COLUMN A; ADD COLUMN A FLOAT;in a sharded table, you only need to executeADD COLUMN A FLOATin other sharded tables. You do not need to execute all of the three DDL statements again.Observe the status of the DM migration when executing the DDL statement. When an error is reported, you need to determine whether this batch of DDL statements will cause data inconsistency.
In the optimistic mode, most of the DDL statements executed in the upstream are automatically migrated to the downstream with no extra effort required. These DDL statements are called "Type 1 DDL".
DDL statements that change the column name, the column type, or the column default value are called "Type 2 DDL". When you execute Type 2 DDL statements in the upstream, make sure that you execute the DDL statements in all sharded tables in the same order.
Some examples of Type 2 DDL statements are as follows:
- Alter the type of a column:
ALTER TABLE table_name MODIFY COLUMN column_name VARCHAR(20). - Rename a column:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;. - Add a
NOT NULLcolumn without a default value:ALTER TABLE table_name ADD COLUMN column_1 NOT NULL;. - Rename an index:
ALTER TABLE table_name RENAME INDEX index_1 TO index_2;.
When the sharded tables execute the DDL statements above, if the execution order is different, the migration is interrupted. For example:
- Shard 1 renames a column and then alters the column type:
- Rename a column:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;. - Alter the column type:
ALTER TABLE table_name MODIFY COLUMN column_3 VARCHAR(20);.
- Rename a column:
- Shard 2 alters a column type and then renames the column:
- Alter a column type:
ALTER TABLE table_name MODIFY COLUMN column_3 VARCHAR(20). - Rename a column:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;.
- Alter a column type:
In addition, the following restrictions apply to both the optimistic mode and the pessimistic mode:
DROP TABLEorDROP DATABASEis not supported.TRUNCATE TABLEis not supported.- Each DDL statement must involve operations on only one table.
- The DDL statement that is not supported in TiDB is also not supported in DM.
- The default value of a newly added column must not contain
current_timestamp,rand(),uuid(); otherwise, data inconsistency between the upstream and the downstream might occur.
Risks
When you use the optimistic mode for a migration task, a DDL statement is migrated to the downstream immediately. If this mode is misused, data inconsistency between the upstream and the downstream might occur.
Operations that cause data inconsistency
The schema of each sharded table is incompatible with each other. For example:
- Two columns of the same name are added to two sharded tables respectively, but the columns are of different types.
- Two columns of the same name are added to two sharded tables respectively, but the columns have different default values.
- Two generated columns of the same name are added to two sharded tables respectively, but the columns are generated using different expressions.
- Two indexes of the same name are added to two sharded tables respectively, but the keys are different.
- Other different table schemas with the same name.
Execute the DDL statement that can corrupt data in the sharded table and then try to roll back.
For example, drop a column
Xand then add this column back.
Example
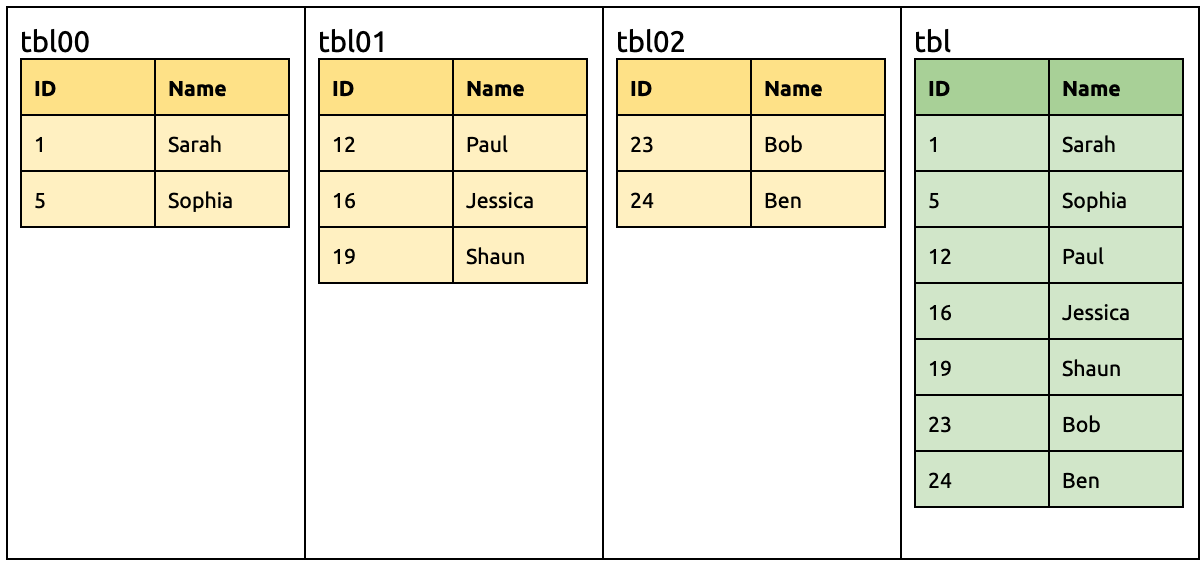
Merge and migrate the following three sharded tables to TiDB:
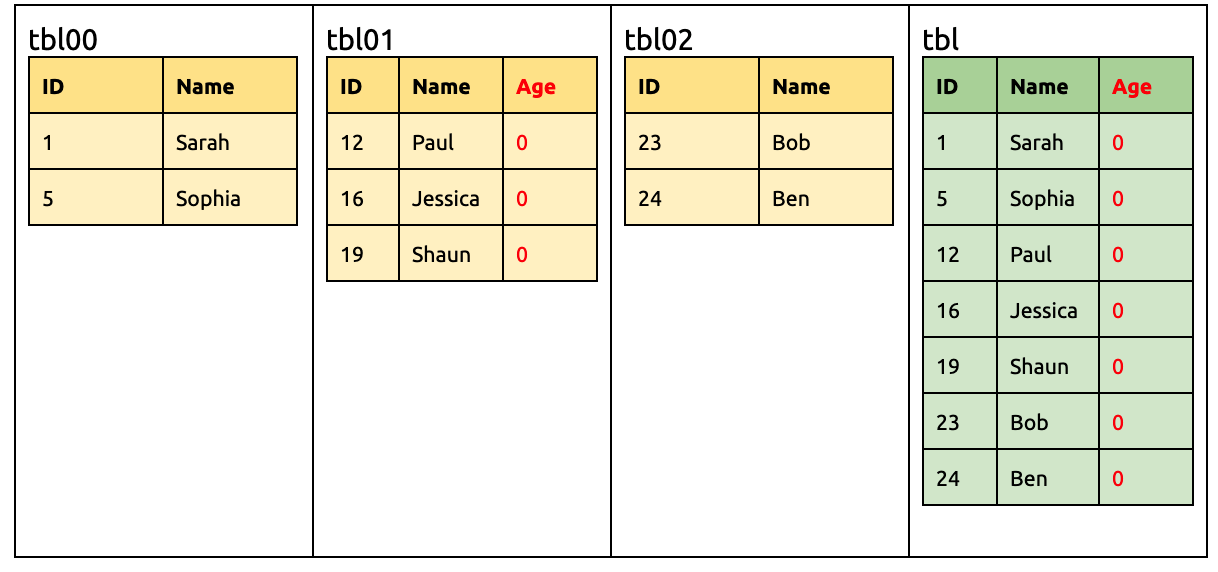
Add a new column Age in tbl01 and set the default value of the column to 0:
ALTER TABLE `tbl01` ADD COLUMN `Age` INT DEFAULT 0;
Add a new column Age in tbl00 and set the default value of the column to -1:
ALTER TABLE `tbl00` ADD COLUMN `Age` INT DEFAULT -1;
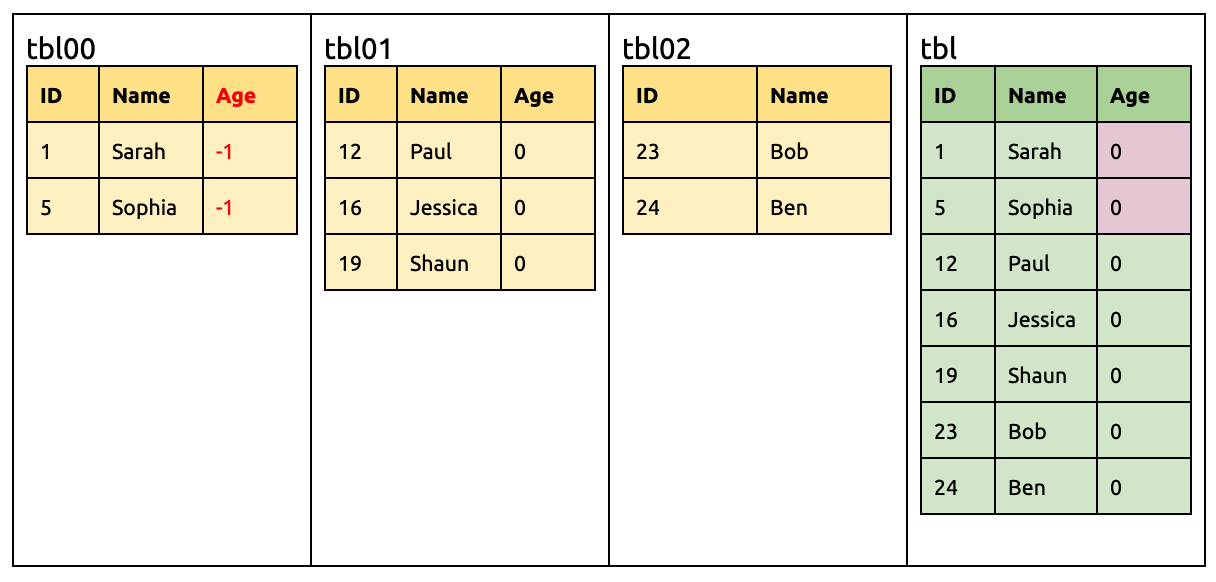
By then, the Age column of tbl00 is inconsistent because DEFAULT 0 and DEFAULT -1 are incompatible with each other. In this situation, DM will report the error, but you have to manually fix the data inconsistency.
Implementation principle
In the optimistic mode, after DM-worker receives the DDL statement from the upstream, it forwards the updated table schema to DM-master. DM-worker tracks the current schema of each sharded table, and DM-master merges these schemas into a composite schema that is compatible with DML statements of every sharded table. Then DM-master migrates the corresponding DDL statement to the downstream. DML statements are directly migrated to the downstream.
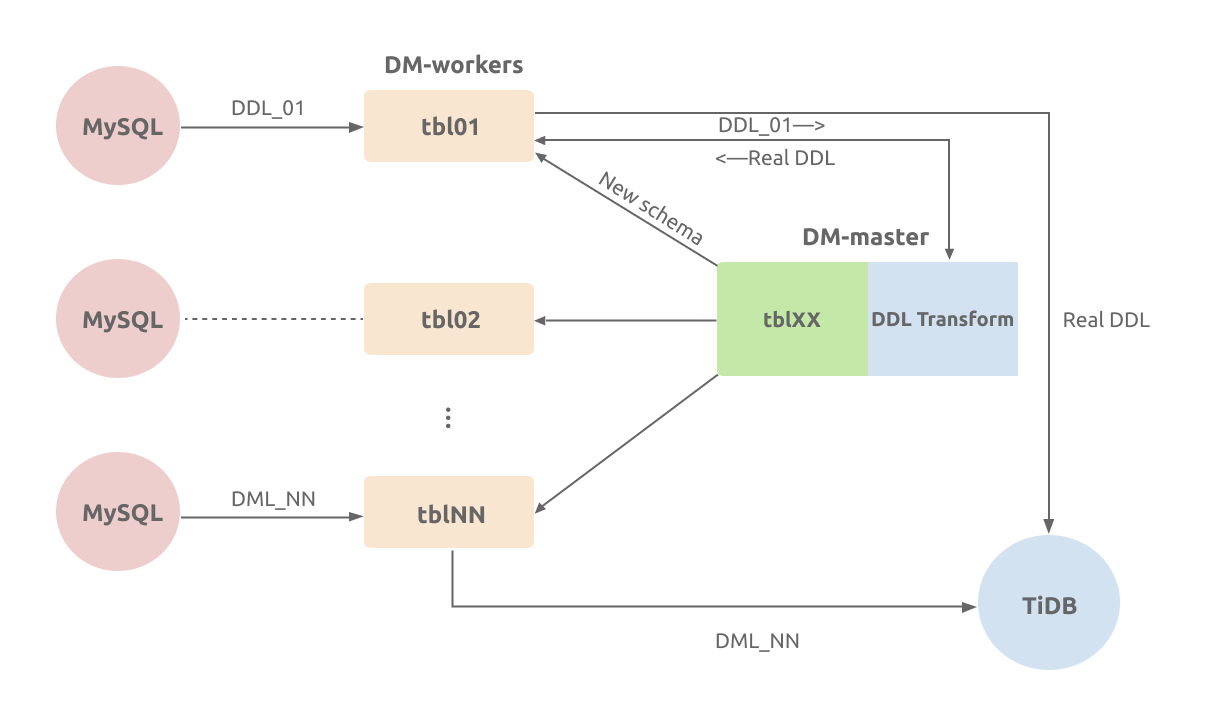
Examples
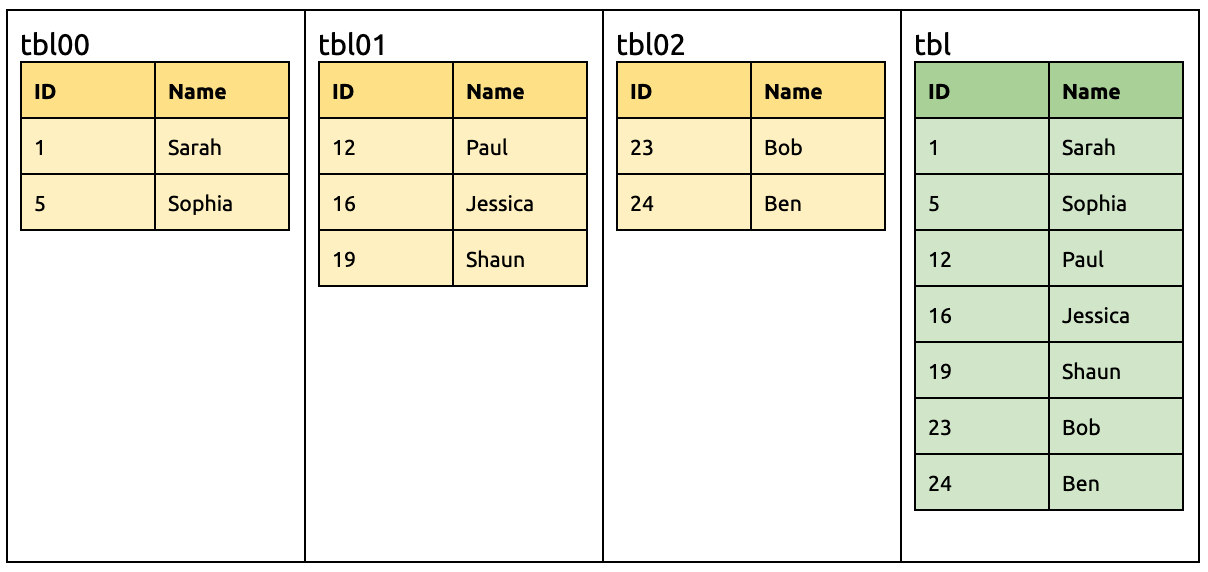
Assume the upstream MySQL has three sharded tables (tbl00, tbl01, and tbl02). Merge and migrate these sharded tables to the tbl table in the downstream TiDB. See the following image:
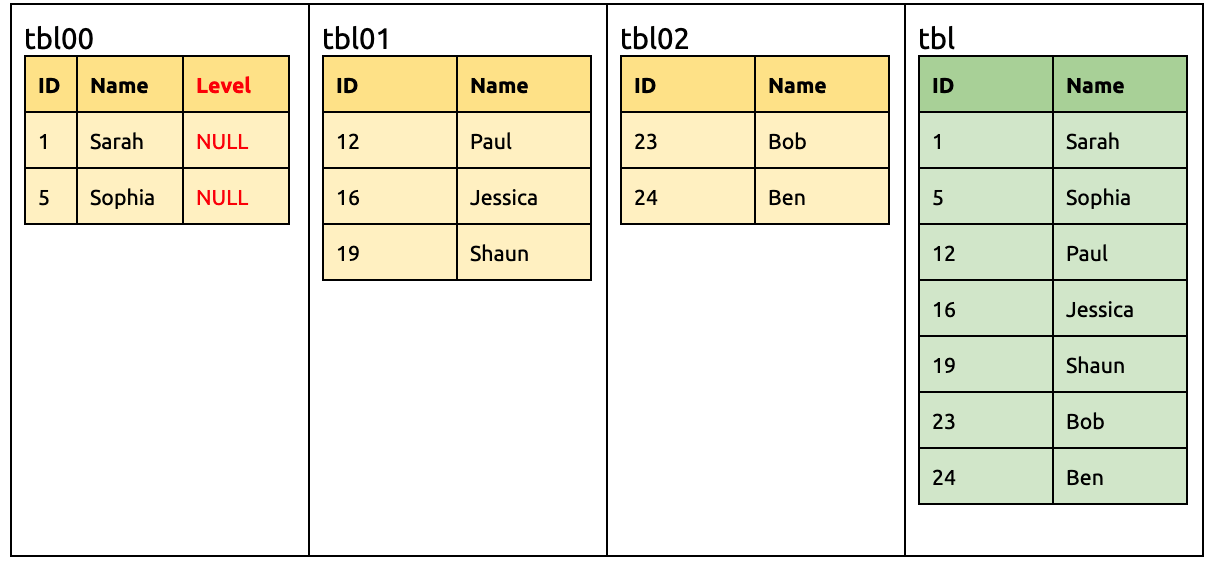
Add a Level column in the upstream:
ALTER TABLE `tbl00` ADD COLUMN `Level` INT;
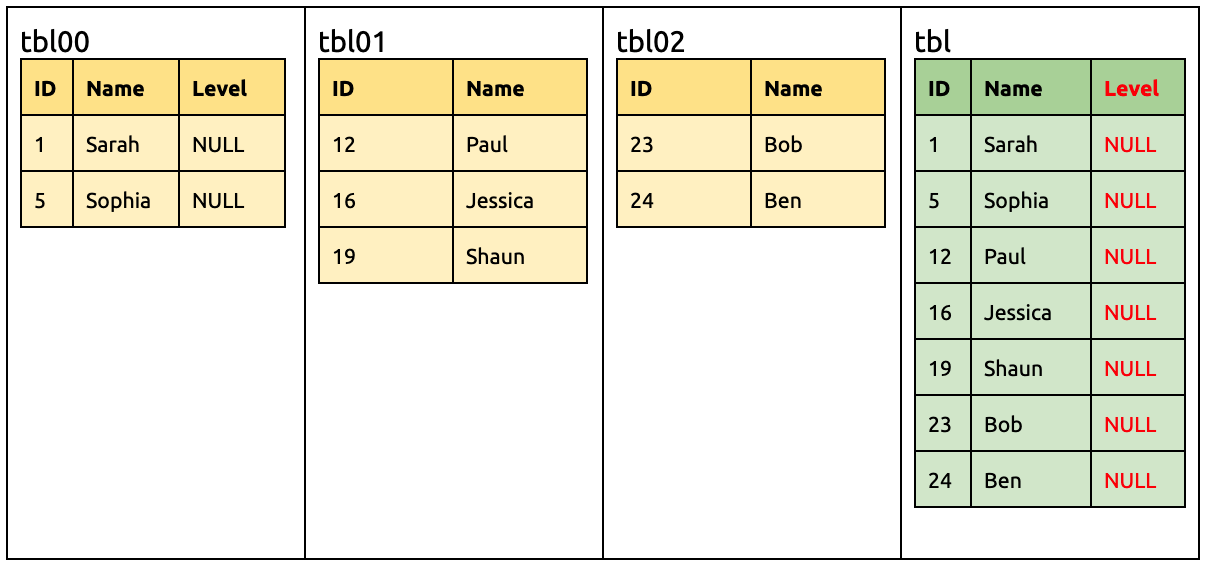
Then TiDB will receive the DML statement from tbl00 (with the Level column) and the DML statement from the tbl01 and tbl02 tables (without the Level column).
The following DML statements can be migrated to the downstream without any modification:
UPDATE `tbl00` SET `Level` = 9 WHERE `ID` = 1;
INSERT INTO `tbl02` (`ID`, `Name`) VALUES (27, 'Tony');
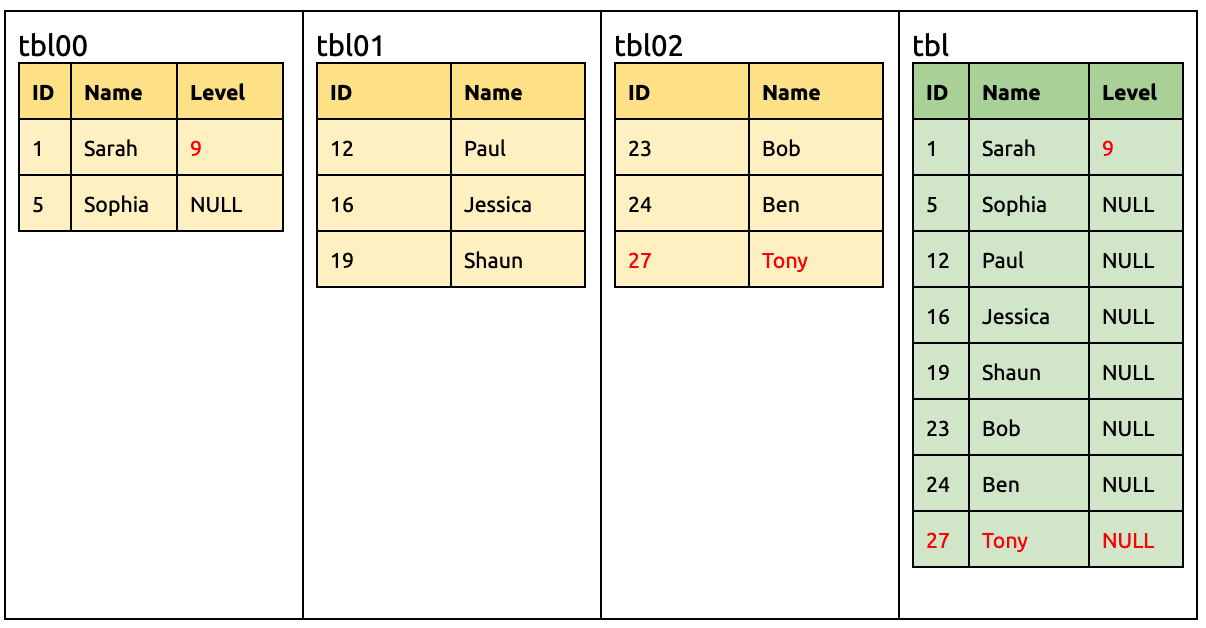
Also add a Level column in tbl01:
ALTER TABLE `tbl01` ADD COLUMN `Level` INT;
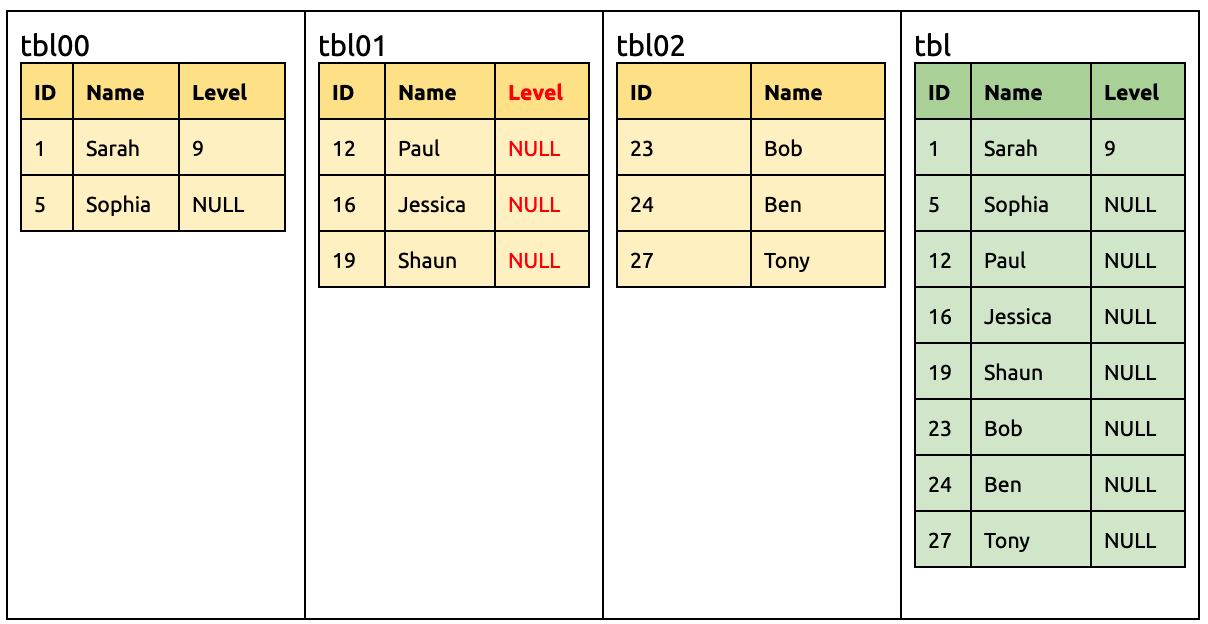
At this time, the downstream already have had the same Level column, so DM-master performs no operation after comparing the table schemas.
Drop a Name column in tbl01:
ALTER TABLE `tbl01` DROP COLUMN `Name`;
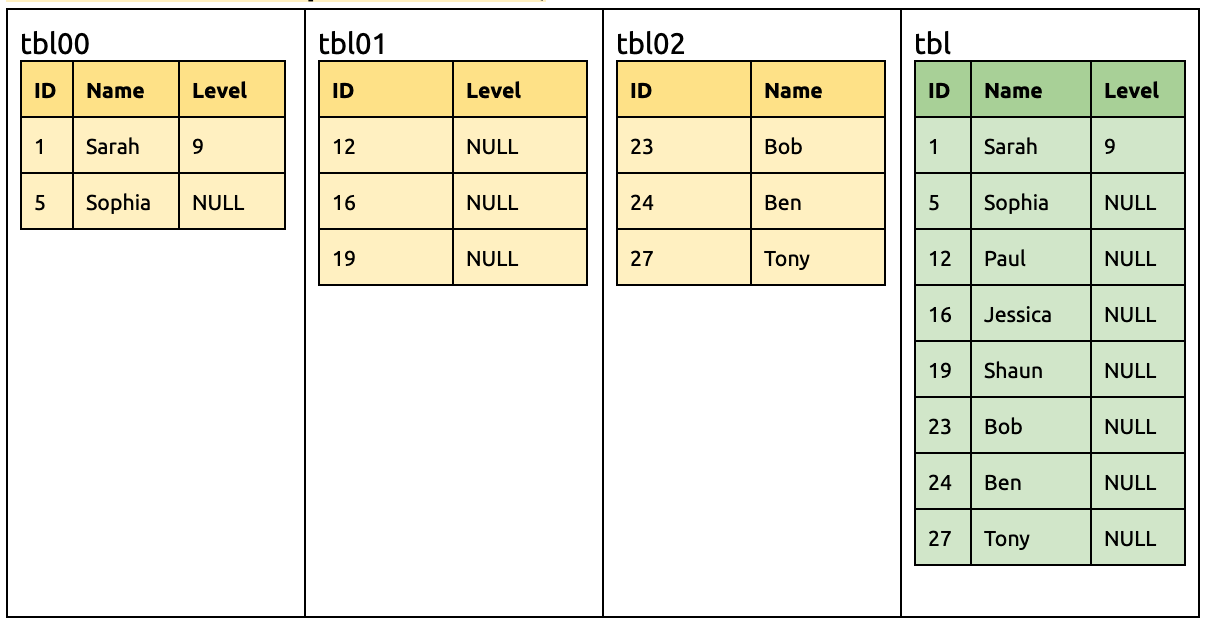
Then the downstream will receive the DML statements from tbl00 and tbl02 with the Name column, so this column is not immediately dropped.
In the same way, all DML statements can still be migrated to the downstream:
INSERT INTO `tbl01` (`ID`, `Level`) VALUES (15, 7);
UPDATE `tbl00` SET `Level` = 5 WHERE `ID` = 5;
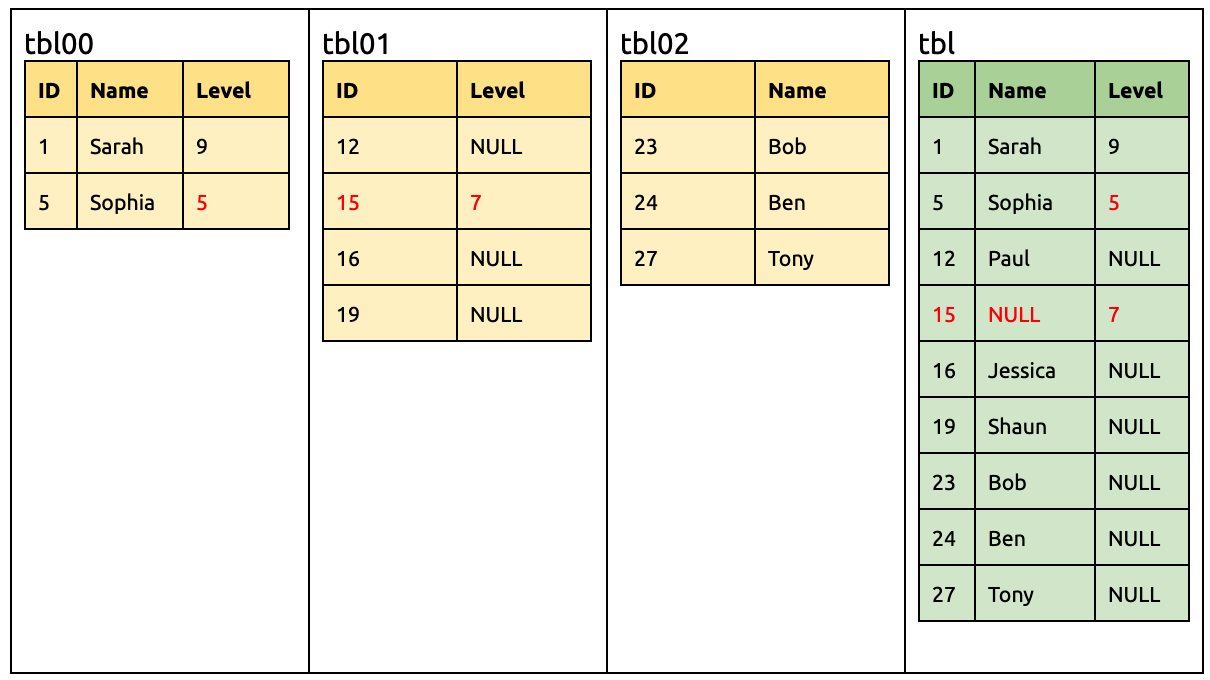
Add a Level column in tbl02:
ALTER TABLE `tbl02` ADD COLUMN `Level` INT;
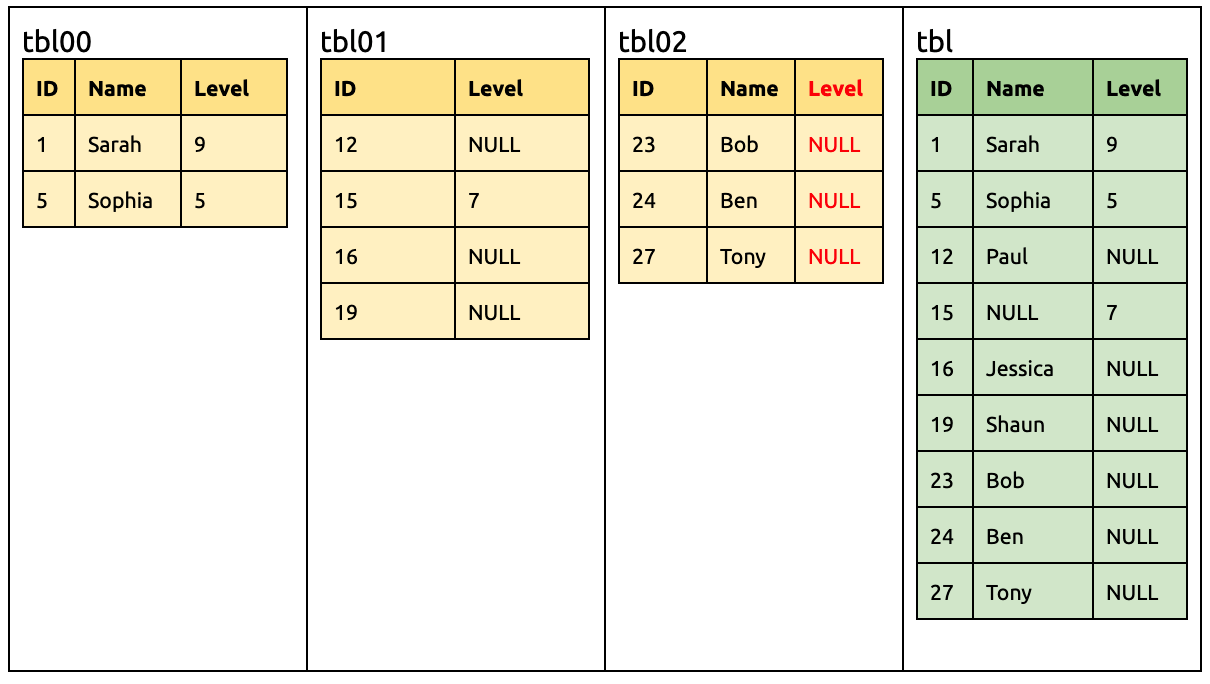
By then, all sharded tables have the Level column.
Drop the Name columns in tbl00 and tbl02 respectively:
ALTER TABLE `tbl00` DROP COLUMN `Name`;
ALTER TABLE `tbl02` DROP COLUMN `Name`;
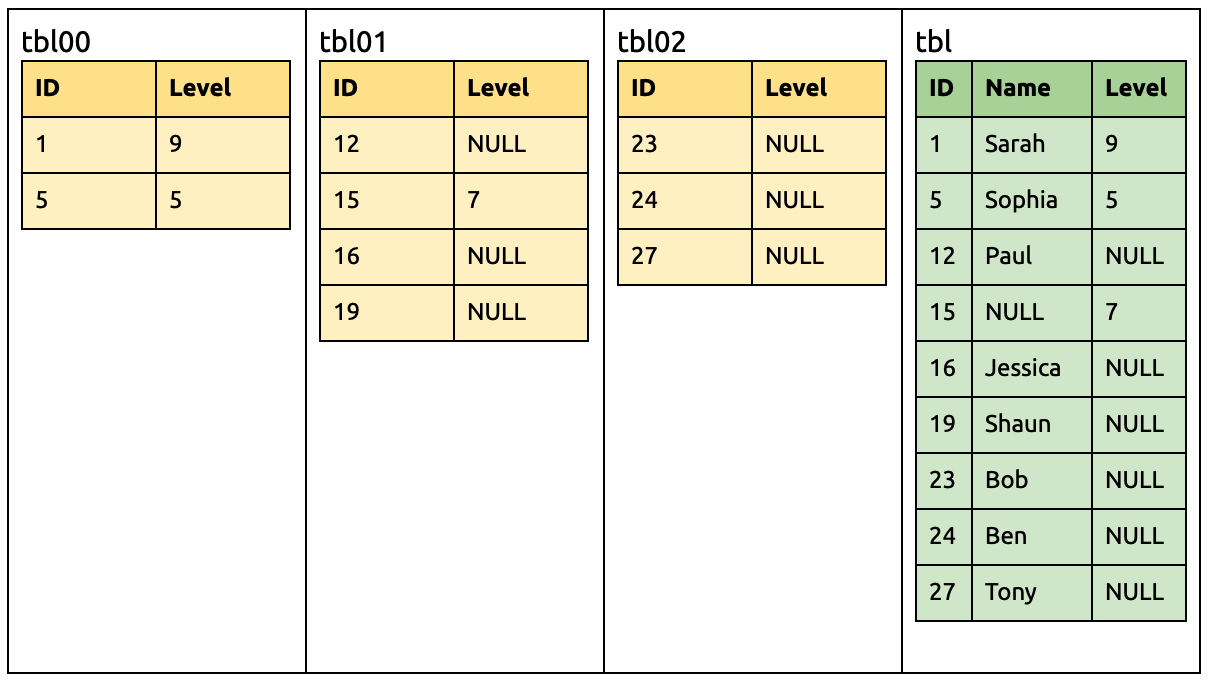
By then, the Name columns are dropped from all sharded tables and can be safely dropped in the downstream:
ALTER TABLE `tbl` DROP COLUMN `Name`;